-
[FACSIMILE_3D human body reconstruction from single image] 리뷰논문 리뷰/오늘의 논문 2022. 2. 19. 18:52
FACSIMILE: Fast and Accurate Scans From an Image in Less Than a Second
2019년도 ICCV에 발표된 논문이다.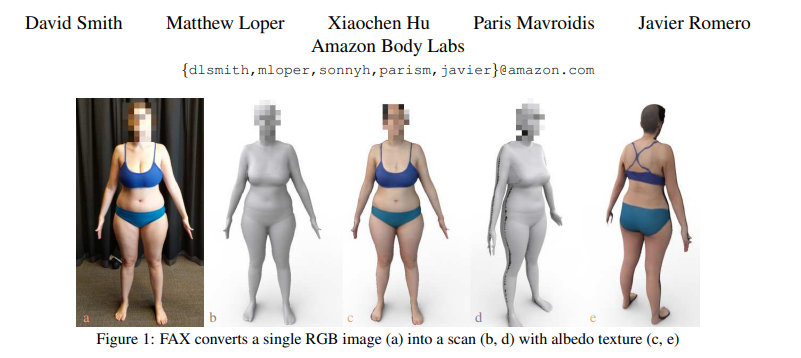
SMITH, David, et al. Facsimile: Fast and accurate scans from an image in less than a second. In:&amp;amp;amp;amp;nbsp; Proceedings of the IEEE/CVF International Conference on Computer Vision . 2019. p. 5330-5339. <Abstract>
근래의 체형 추론 방법들은 디테일이 떨어지고, 많은 이미지가 필요하다. 그렇기에 우리는 FAX(FACSIMILE)를 제안한다. 이것은 한장의 사진으로 부터 신체의 디테일을 추론하는 방법론이고, 이로인해 사람을 가상에서 재현하는 것에 대해 문턱을 낮춘다. 역설적이게도, FAX의 메인 loss는 normal에 대한 픽셀당 로스이다, 깊이의 픽셀당 로스가 아니다. 이것은 깊이 감독(supervision) 없이도 신체의 기하학적 디테일을 만들게하기 가능하게 만든다. 우리는 우리의 접근방법을 정성적 정량적으로 평가하고, 기존 SOTA모델과 비교하였다.
=> 밑줄 내용이 이 논문의 가장 큰 기여가 아닐까 생각한다. 뒤에 실험에서도 나오겠지만 normal에 대한 것이 주된 결과이다.
<1. 서론>
RGB-D 센서들은 전통적인 방법들의 3D human body reconstruction 문제들을 극복해왔으나, RGB카메라보다 대중적이지 않다(widespread). 근래의 단일 RGB 이미지 기술은 디테일이 부족하다. 이러한 표현의 디테일을 다루기 위해, 우리는 기하 추론에 있어서 근래의 이미지 대 이미지 변환 기술(image to image translation)을 적용하였다.
단일의 깊이맵은 전체 아바타와는 거리가 멀기 때문에, 우리는 정면과 후면의 기하와, 알베도를 추론하도록 시스템을 확장하였다. 우리는 사람의 뒷면을 추론하도록 네트워크를 학습시킴으로서 픽셀당 두 개의 값을 얻는다는 아이디어를 차용한다. 이전의 연구와는 다르게, 텍스처에 제한을 두지 않고, 후면 깊이와 법선도 추정한다. 현재의 세부적인 방법들은 일반적으로 실행하는 데 몇 분이 걸리지만 기하와 텍스처를 포함하는 거의 완전한 스캔을 1초 이내에 계산한다.
우리는 세 가지 기여가 있다.
1. 우리는 단일 이미지에서 전체 스캔을 계산하는데, 이는 세부 스캔을 생성하는 현재 방법보다 훨씬 더 빠르다.
2. 이러한 스캔이 게임, 이미지 측정 및 가상 영상회의와 같은 응용 프로그램에 유용할 수 있는 추가 시간(10초 미만)이 거의 없이 변형 가능한 세부 아바타로 변환될 수 있는 방법을 보여준다.
3. 우리는 우리 방법의 효율성을 최첨단 다중 이미지 방법과 정량적으로 비교하고 정성적 및 정량적 ablation study를 수행하여 설명한다.
=> 본 연구의 base_line은 Pix2PixHD로서 image to image translation 방식을 적용하였다. 또한 특이한 점은 앞면과 뒷면을 추론하여, 붕어빵처럼 앞뒤를 생성시키는 것이다. 이는 이 이후에 나온 PIFUHD에서도 나오는 개념이며 PIFUHD에서 본 논문을 참고하여 개선했다고 언급한다.
<2. 관련 연구>
1. Geometry estimation from a single-photo
2. Single-photo body estimation
3. Single-photo face estimation
=> PIFU도 그렇고 대부분의 3d body reconstruction 논문들은 face 논문들을 많이 참고 한다. (full 내용은 아래에 원본의 번역본 링크를 참조)
<3. Method>
우리의 목적은 단일 RGB 이미지로 세밀한 3차원 스캔을 추정하는 것이다. 우리는 이것을 이미지 대 이미지 변환을 통해 다룰 것이고, 이미지를 깊이 그리고 알베도 값으로 변환 할 것이다. 좀더 구체적으로, 우리는 이러한 추정을 신체의 앞과 뒤를 할 것이다.
=> 단일 이미지를 이미지 대 이미지 변환을 통하여 앞과 뒤의 알베도 값을 추론한다.
<3.1 Albedo estimation>
우리의 아키텍처는 이미지 대 이미지 변환의 일환인 cGAN에 기반하였다(cGAN의 모델중 하나인pix2pixHD를 base_line 네트워크로 사용함). semantic segmentation과 이미지 편집, 그들의 "enhancer"네트워크는 생략한다. 따라서 우리는 우리의 생성기를 residual block들로 구성된 다운샘플링 구간과 피처맵을 저장하고 이를 입력 해상도로 복원하는 업샘플링 구간으로 완성된 그들의 "global generator"를 사용하여 생성기를 정의한다. 우리는 checkerboard artifacts를 피하기 위해 전치된 컨볼루션을 업샘플-컨볼루션으로 교체하여 약간의 수정을 했다.
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs loss는 3가지로 구성되어있다. LGAN, LFM, LVGG.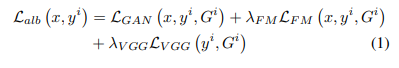

SMITH, David, et al. Facsimile: Fast and accurate scans from an image in less than a second. In: Proceedings of the IEEE/CVF International Conference on Computer Vision . 2019. p. 5330-5339.
전면과 후면의 알베도 값의 loss는 동일하다. 이미지의 합성 훈련 데이터와 해당 전면 및 후면 알베도가 주어지면 두 개의 알베도 세트에 해당하는 6개의 채널로 G를 추정한다. 총 손실은 전면과 후면에 적용된 손실의 합계이다.
=> 사실 네트워크 아키텍처는 크게 변한것도 없고 loss도 마찬가지이므로 데이터셋이 중요할 것으로 보인다. 그런데 데이터셋이 좀 아쉽다. (in lab이라는 표현을 쓰고 공개를 안한 것들이 있기 때문에..뭐.. 공개한것만으로도 충분하다고 하면 저는 할말이 없긴합니다.. ㅎㅎ;)
<3.2 Depth estimation>
Motivation 앞서 설명한 바와 같이 깊이의 직접적인 추정은 여러 가지 이유로 어렵다.
1. 스케일과 카메라까지의 거리 사이에는 사람도 해결하기 어려운 모호함이 있다.
2. 카메라까지의 이 거리는 모양 세부 사항보다 훨씬 더 큰 데이터 변동을 수반한다.
따라서, 깊이 loss는 네트워크 작업이 카메라까지의 전체 거리를 해결하도록 권장하며, 이는 우리의 목적에 매우 도전적이고 대부분 관련이 없는 문제이다. 대신, 규모의 모호성에 불변하는 로컬 표면 기하학을 추론하는 데 초점을 맞춘다.
초기 실험에서 우리는 이미지 번역 네트워크의 직접 적용을 통해 상세한 표면 법선을 추정할 수 있었다. 그러나 법선을 강력한 깊이에 효율적(efficiently)으로 통합하는 것은 음영 문헌에서 모양의 핵심에서 어려운 문제이다. 추론된 일반 이미지의 통합은 어렵고 비용이 많이 들지만 역 연산자는 간단하다. 즉, 공간 도함수이다. 공간 도함수는 국소적 차이 필터가 있는 고정 계층으로 간단하게 구현될 수 있다. 이러한 레이어를 추정된 법선 바로 뒤에 배치함으로써 이전 결과가 깊이에 해당하도록 암시적으로 강제한다. 고전적인 통합 접근 방식과 유사하게 이것은 깊이 ground truth 데이터가 없는 경우에도 깊이를 추론할 수 있지만 명시적 통합으로 인해 발생하는 추가 계산 비용은 없다.
=> 저자에게 물어봐야 정확하게 알 것 같다. 다만, 추론해보면 아마도 normal자체가 법선을 표현하므로, 곡률을 미분했다는 뜻이 아닐까 생각해본다.
Losses 우리의 depth 아키텍처 에서 출력은 3개의 채널이며, i는 앞면 또는 뒷면을 나타내는 전면 및 후면 깊이 Gid와 깊이가 유효한 위치를 나타내는 마스크 Gm을 나타낸다. 전면 및 후면 깊이는 깊이를 법선 Gin = δ(Gid, Gm, f)로 변환하는 공간 미분 네트워크 δ로 처리됩니다. 이 공간적 미분은 원근 왜곡을 수정하기 위해 초점 거리 f(훈련 및 테스트 데이터에서 고정된 것으로 간주)에 따라 달라진다. 또한 미분 연산자는 네트워크에서 생성된 마스크 Gm을 통합하여 경계를 통해 미분하지 않도록 합니다. 깊이가 유효하지 않은 영역에서는 일정한 법선 값이 생성된다.
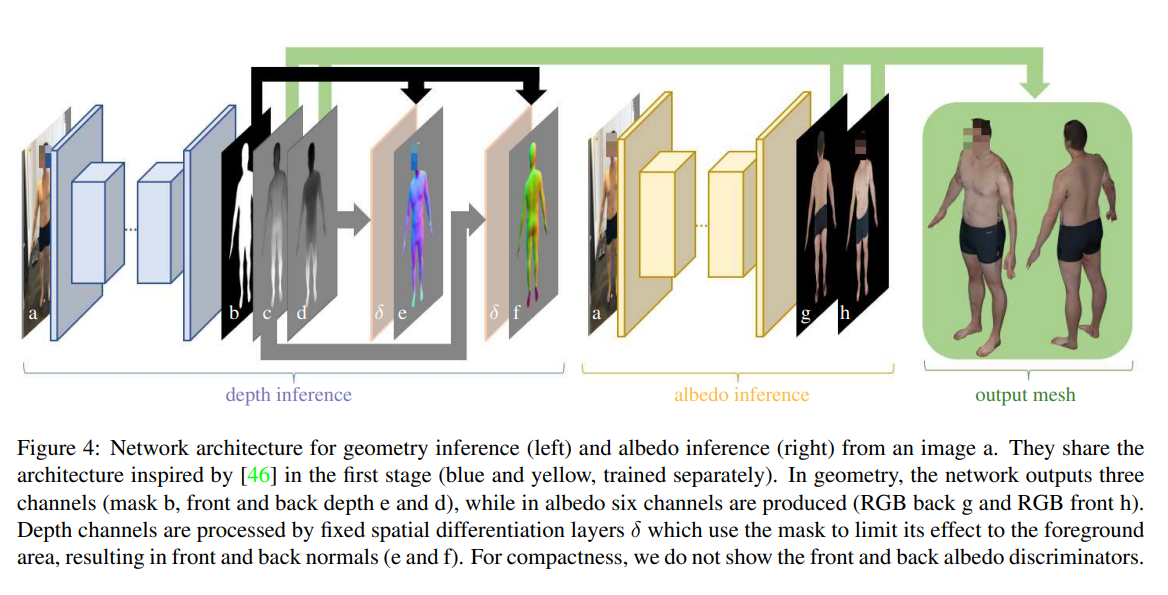
SMITH, David, et al. Facsimile: Fast and accurate scans from an image in less than a second. In:&amp;amp;amp;amp;nbsp; Proceedings of the IEEE/CVF International Conference on Computer Vision . 2019. p. 5330-5339.
알베도(또는 일반적으로 색상)는 적대적 loss로부터 분명히 이익을 얻는 것처럼 보이지만 기하 복원 에 대해서는 그렇지 않은 것 같다. 우리의 경험에서 Lalb의 적대적 loss는 깊이 및 normal 추정 문제에 적용할 때 노이즈가 들어가고, 보이지 않는 조건에 대한 견고성을 감소시킨다. 이러한 이유로 기하학 추정 목표의 깊이 Ld 및 법선 Ln 항은 적대적 loss를 L1 손실로 대체합니다. LVGG는 훈련 불안정을 유발할 수 있는 (무제한) 깊이 값의 정규화가 필요하므로 깊이 표현에 적용되지 않는다. 총 손실은 법선 및/또는 깊이에 적용된 이 기하학적 손실을 잠재적으로 포함할 수 있다.
=> 그러니깐 노말 로스랑 뎁스로스 L1로스로 바꾸고 뎁스는 해보니깐 vgg 문제 생기니깐 아래와 같이 로스 설정했다 이말입니당 ㅎ
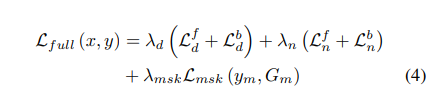
SMITH, David, et al. Facsimile: Fast and accurate scans from an image in less than a second. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. p. 5330-5339.
<3.3 Estimating Dense Correspondence>
이전 섹션에서 설명한 시스템은 본질적으로 불완전한 픽셀당 깊이 값을 생성한다. 또한, 이러한 값은 픽셀당 생성되기 때문에 의미론적 의미(코, 팔꿈치 등의 우리가 생각하는 인체의미)가 없다. 이 섹션에서는 인간의 모양과 자세에 대한 통계 모델인 SMPL을 기반으로 신체 기하학의 보이지 않는 부분을 추론하기 위해 Detailed Full-Body Reconstructions of Moving People from Monocular RGB-D Sequences 설명된 메쉬 정렬 프로세스를 채택한다.
정렬 프로세스는 메시를 변형하여 이전 섹션에서 추론된 스캔에 가깝고 SMPL 몸체 모델에 따를 가능성도 있다. Detailed Full-Body Reconstructions of Moving People from Monocular RGB-D Sequences와 유사하게, 우리는 메시로 스캔 거리 항 Es, 얼굴 랜드마크 항 Eface, 두 포즈 및 모양 사전 Epose 및 Eshape, 메쉬항 Ecpl의 가중 평균으로 구성된 손실을 최소화한다.
Es는 스캔과 메쉬 표면의 가장 가까운 점 사이의 제곱 3D 거리에 페널티를 준다. Eface는 이미지에서 감지된 얼굴 랜드마크(스캔과 암시적으로 일치)와 SMPL에서 미리 정의된 랜드마크 위치 사이의 제곱 3D 거리에 페널티를 준다. Ecpl은 자유롭게 변형할 수 있는 메쉬가 최적화된 포즈 및 모양 매개변수가 암시하는 모델에 가깝게 유지되도록 권장한다. Epose와 Eshape는 SMPL 매개변수와 CMU 및 SMPL 데이터 세트에서 추론된 가우스 분포 사이의 Mahalanobis 거리에 페널티를 적용하여 결합 모델의 포즈와 모양을 정규화한다.
단일 보기 및 보정되지 않은 다시점 형상 추정에서 일반적이므로 우리의 결과는 대상 축척을 정확하게 복구할 수 없다. SMPL은 임의의 스케일로 스캔을 맞출 수 없으므로 메쉬를 최적화하기 전에 먼저 스캔을 고정 높이로 스케일링한 다음 최적화된 메쉬에 역 스케일을 적용하여 원래 참조 프레임으로 되돌린다.
깊이 추정기를 훈련할 때 깊이 손실은 전역 제약 조건으로 작용하여 전면 및 후면 스캔이 일관된 규모로 추정되도록 강제한다. 훈련 중에 이 손실이 생략되면 전면 및 후면 스케일이 반드시 일관성이 있는 것은 아니므로 메쉬 정렬 중에 상대적 스케일을 최적화해야 한다. 이것은 뒤쪽 정점에 적용되고 메시와 함께 최적화되는 단일 추가 자유 스케일 변수를 도입하여 수행할 수 있습니다. 실험을 설명할 때 이 옵션을 opt back라고 한다.
=> Detailed Full-Body Reconstructions of Moving People from Monocular RGB-D Sequences의 가정을 따랐다
<4. Experiments>
<4.1 Training and evaluation details>
알베도 추정시 512X512 random crop사용. 다중 스케일 판별기는 1x, 1/2x 및 1/4x 해상도에서 이미지를 처리. 손실은 pix2pixHD와 같이 가중됨. 깊이 추정을 위해 720 × 960 이미지를 학습하고 초점 길이는 720픽셀임. 우리는 카메라까지의 고정된 거리를 가정하지 않습니다. 알베도 및 깊이 추정 네트워크는 모두 배치 크기가 1인 180k 단계로 훈련되고 입력 이미지는 가우스 블러, 가우스 노이즈, 색조, 채도, 밝기 및 대비로 증가됨. 훈련 과정은 V100 Tesla GPU를 사용하는 경우 약 48시간이 소요됨. 평가는 720 × 960 이미지에서 수행됨. 두 네트워크 중 하나의 단일 정방향 패스는 약 100밀리초가 걸리는 반면 SMPL을 스캔에 맞추는 데는 7초가 걸림.
=> 데이터셋 보면 이해됨
<4.2 Datasets>
우리는 합성 데이터 세트에 대해서만 훈련하고 "in lab"에서 수집한 실제 이미지에 대해 테스트한다. 옷을 입고 "A" 자세로 서있는 데이터. 40,000개의 합성 이미지 튜플을 렌더링한다(검증 및 테스트를 위해 각각 1% 보류). 본체에는 SMPL로 합성된 기본 저주파 형상과 실험실에서 캡처한 고주파 변위가 있다. SMPL 형상 매개변수는 CAESAR 데이터 세트에서 샘플링되고 포즈는 (a) CAESAR 포즈와 (b) A 포즈에서 편안한 자세까지 팔이 다양한 실험실 내 스캔 포즈 세트에서 샘플링된다. 실험실에서 촬영된 사람들의 3D 사진 측량 스캔에서 파생된 텍스처 및 변위 맵은 무작위로 샘플링되어 기본 몸체에 적용되어 입력 및 출력 공간의 다양성을 높인다.
카메라는 원점에서 0으로 고정되고 몸체는 카메라를 약간 아래쪽으로 기울이면서 약 2미터의 거리를 시뮬레이션하기 위해 무작위로 변환 및 회전된다. 구체적으로, 변환은 x ~ [-0.5, 0.5], y ~ [0.0, 0.4], z ~ [-2.2, −1.5]에서 샘플링되고 회전은 x ~ [-9.0에서 오일러 각으로 샘플링됨. 35], y ~ [-7, 7], z ~ [-2, 2], yxz 순서로 적용됨. 배경 이미지는 사람이 포함된 이미지를 제외하고 OpenImages에서 가져옴.
우리는 세 가지 광원을 사용함: 이미지 기반 환경 조명(배경 이미지를 광원으로 사용), 점 조명 및 직사각형 영역 조명. 각 렌더에 대해 모든 조명의 강도, 포인트 및 영역 조명의 위치와 색온도, 영역 조명의 방향과 크기, 바디에 있는 셰이더의 반사도와 거칠기를 무작위로 샘플링함. 모든 광원은 레이트레이싱 그림자를 드리우며 일반적으로 영역 및 점 광원에서 가장 잘 보임.
<4.3 Visual Evaluation>
기준선으로 L1 손실 함수를 사용하여 정면 깊이의 직접 추정을 고려한다. 깊이에 대한 L1 손실과 법선에 대한 L1 손실로 훈련된 모델을 비교하여 자연 테스트 이미지에서 추정된 메시를 보여준다. 깊이만 손실한 결과는 사용할 수 없는 것처럼 보이지만 법선만 손실한 결과는 부드럽고 강력하며 인상적인 양의 디테일을 캡처한다. 따라서 인체의 상세한 깊이 추정의 경우 깊이에 대한 직접적인 손실은 충분하지 않은 반면 표면 법선의 손실은 강력하고 상세한 깊이 추정을 생성하기에 충분하다. 그러나 법선의 손실은 출력을 로컬로 제한하기 때문에 기하 스케일에 맞지 않는다. 깊이의 손실은 기하학의 품질에 중요하지 않지만 그럴듯한 인간 규모의 공간으로 출력을 장려한다.
팩스의 한 가지 장점은 단일 이미지에서 미묘한 모양 세부 사항을 추출할 수 있다는 것입니다. 복구된 모양은 거의 모든 예에서 허리, 엉덩이 및 가슴에서 관찰된 바와 같이 복잡하고 개인적이다. 이것은 볼록 껍질, 복셀 또는 SMPL 모양 매개변수에 기반한 방법으로는 달성하기 어렵다. 이미지 윤곽에 맞게 모양을 명시적으로 최적화하는 방법도 기본 최적화가 데이터와 기본(지나치게 부드러운) 모델 사이의 절충안을 찾아야 하기 때문에 이러한 세부 수준을 복구하지 못한다. FAX에서 얻은 세부 정보는 대부분 윤곽선에서 볼 수 있지만 측면 렌더링은 이 세부 사항이 신체 모양에 걸쳐 일관된 방식으로 재구성되어 실루엣 및 이미지 음영과 일관된 가슴 및 배 모양을 재현함을 보여준다.
그림자 및 문신과 같은 시각적 불연속성은 도전 과제이다. 고전적인 쉐이프-프롬 셰이딩(shape-from-shading) 방법은 오해의 소지가 있는 시각적 경계에 능선 인공물을 도입하는 것으로 유명하다. 우리의 방법은 문신이 있는 경우 깨끗한 기하를 생성한다. 그리고 우리의 방법은 날카로운 그림자에 대한 불변성을 나타낸다. 우리는 이 불변성을 훈련 데이터 세트의 다양성에 거의 전적으로 신뢰한다. 훈련에서 날카로운 그림자를 도입하기 전에 그림자 주변의 능선 아티팩트가 테스트 출력에서 일반적이었다.
공간 스캔 구멍은 추가 과제이다. 많은 고품질 스캐너 설정과 마찬가지로 원시 추정 스캔은 전면 및 후면을 향한 깊이 맵 사이의 이음매로 눈에 띄게 보이는 모든 지오메트리를 캡처하지 않는다. 이 문제는 아바타를 맞추는 동기 중 하나이다. 재배포 가능성을 제공하는 것 이상으로 구멍 폐쇄 및 스캔 완료를 제공한다.
<4.4 Quantitative evaluation on Dynamic FAUST>
Sota 모델들과 비교 하였음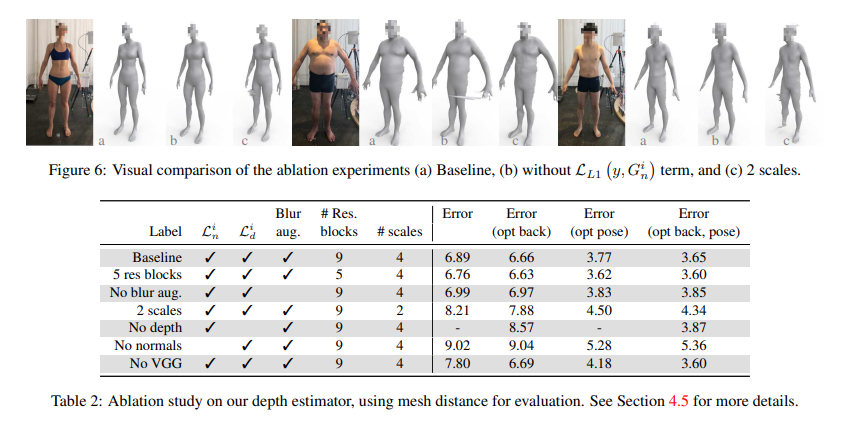
SMITH, David, et al. Facsimile: Fast and accurate scans from an image in less than a second. In:&amp;amp;amp;amp;nbsp; Proceedings of the IEEE/CVF International Conference on Computer Vision . 2019. p. 5330-5339. <4.5 Ablation Study>
1. Loss 값들에 대해서 수행
2-1. 네트워크 residual block들의 수 대해서 수행
2-2. downsampling (scales)의 수에 대해서 수행
3. 훈련시 블러처리한 데이터 Augmentation에 대해 수행
Loss설정에 있어서 normal, depth 모두 성능에 영향을 미쳤다. 특히, normal(L1, Lvgg)에 대한 중요성이 주목할만 하며, depth Loss를 제거하는 것보다 좋지 않았다.
residual block수 줄이면 정확도가 증가하긴 하나, 무시할만한 수준이다.
다운샘플링의 수가 적으면 노이즈가 유지되어 정확도가 저하되었다.
blurr 증대는 수치적 영향은 적지만 스파이크와 구멍을 만들어 텍스처 스캔을 빠르게 생성하는 데 사용할 수 없다는 것을 관찰했다.
=> normal에 대한 loss가 가장중요함. 나머지는 성능에 크게 영향을 끼치지 않음.
<5. Conclusions>
FAX는 이전에 볼 수 없었던 세부 수준의 단일 RGB 이미지에서 전신 기하 및 알베도를 추정한다. 이 품질은 크게 두 가지 주요 요인에 따라 달라진다.
1. 우리는 복셀(voxel), 볼록 껍질(convex hull) 또는 바디 모델과 같은 표현을 통해 출력을 간접적으로 사용하지 않는다. 이를 통해 다른방법보다 빠르게 이미지 변환 네트워크를 통해 원래 픽셀 정의에서 디테일을 복원 할 수 있다.
2. 우리의 기하 추정(geometry estimation)은 표면 법선(surface normals)의 역할에 크게 의존하며 깊이 정보가 없을 때 표면 법선만으로도 어떻게 그럴듯한 몸체를 생성할 수 있는지 보여준다. 향후 작업을 위해 훈련 데이터를 개선하면 정면 포즈나 최소한의 옷과 같은 현재 방법의 많은 제한 사항을 극복할 수 있다고 믿는다. 우리는 신속하고 데이터 중심적인 방식으로 스캔 기하와 텍스처의 이음새를 제거하고자 한다.
=> 재미있는 점은 다른 회사나 대학들은 이 분야에서 residual block대신 hourglass나 다른 백본들을 사용하는데 아마존은 residual을 참 좋아하는 것 같다.
본 논문이 뒤에 나오는 3d human body reconstruction 분야 (non-parametic)에서의 연구들에 영향을 개인적으로는 많이 끼치지 않았나 생각한다. normal map에 대한 추론 발상이나(물론 3D분야에서는 늘상 있던 아이디어이긴하지만) 앞뒤를 생성시켜서 합친 다는 발상 그리고 그것에 대한 실험은 정석적이라고 생각하고 배울점이 많다. 아쉬운점이 있다면, 데이터셋에 대한 아쉬움이 크다. 논문에서도 언급되지만 아마도(뇌피셜) 모든 상황에 Robust하게 되지는 않을것이라고 생각한다.
추가 공부필요)
- albedo map
- normal map
- checkerboard artifacts
- High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
- Detailed Full-Body Reconstructions of Moving People from Monocular RGB-D Sequences
번외) 추가 스크립트
https://www.amazon.science/latest-news/the-science-behind-the-amazon-halo-band-body-feature
요약을위해 자체 번역본을 만들었다(의역과 오류 주의)
https://github.com/ylab604/3D-human-body-paper-review'논문 리뷰 > 오늘의 논문' 카테고리의 다른 글