-
pixelNeRF : Neural Radiance Fields from One or Few Images (paper review)논문 리뷰/오늘의 논문 2022. 8. 12. 00:44
😎 굉장히 오랜만에 돌아온 논문 리뷰입니다. 😎
틀린점 댓글 마음껏 달아주시고, 어떠한 피드백도 달게 받겠습니다.
리뷰 작성중이며 아마 후속으로 코드리뷰까지 진행 될 것입니다.
👨💻 ECCV 2020뒤로 neural rendering 분야가 확실히 대세가 된 느낌이 강합니다. 이미지 생성쪽에서는 DDPM이 대세가 되었고 보면 2020년도에 굵직한 주제들이 많이 등장하였습니다. 2022 CVPR에 대한 논문들을 모두 훓어 보지는 못했지만 당분간 NeRF류 논문 3D deeplearning 논문 을 자주 리뷰 하고자 합니다.
pixelNeRF : Neural Radiance Fields from One or Few Images
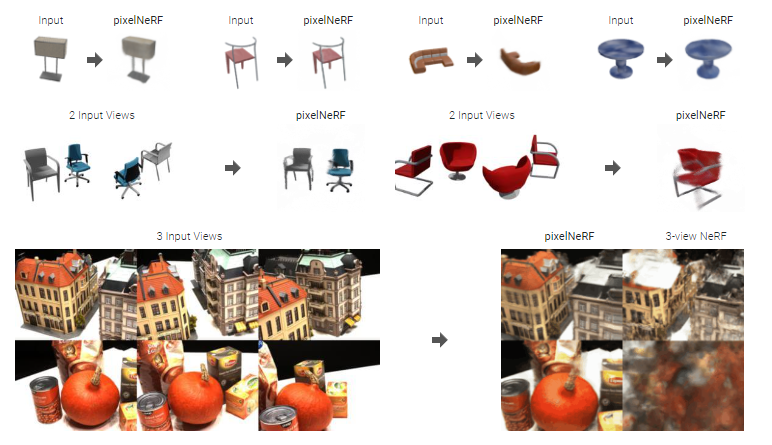
cvpr 2021 pixelNeRF Abstract
- NeRF 구성하기 위한 기존 접근 방식에는 모든 장면에 대한 표현을 독립적으로 최적화하는 것이 포함되며, 많은 보정된 뷰와 상당한 계산 시간이 필요합니다.
- 이러한 단점을 해결하기 위해 fully convolution 방식으로 이미지 입력에 대한 NeRF를 조절하는 아키텍처를 도입 하였습니다.
- 이를 통해 네트워크는 여러 장면에 걸쳐 훈련되어 사전에 장면을 학습할 수 있으므로 적은 수의 장면에 feed-forward 방식으로 novel view synthesis를 할 수 있습니다.
Introduction
기존 NeRF의 문제점 지적
- 많은 수의 posed image가 필요하고 각 장면에 대해 최적화(per scene optimization) 해야하기 때문에 오래걸립니다. 따라서 실용적이지 않습니다.
- 이미지 feature가 사용되지 않는 NeRF와 다르게 pixelNeRF는 픽셀에 정렬된 공간 이미지 feature가 input에 사용됩니다.

구체적인 Frame work flow
- input 이미지로 부터 fully convolutional 이미지 feature grid를 계산하여 NeRF를 조정하였습니다.(약간의 의역 condition을 조정으로 해석하였음).
- 뷰 좌표 프레임에서 관심 있는 각 쿼리 공간 점 x 및 보기 방향 d에 대해 투영 및 bilinear interpolation을 통해 해당 이미지 feature를 샘플링합니다.
- 쿼리 사양은 밀도와 색상을 출력하는 NeRF 네트워크로 이미지 특징과 함께 전송되며, 여기서 공간 이미지 특징은 각 레이어에 잔차로 제공됩니다.
- 둘 이상의 이미지를 사용할 수 있는 경우 입력은 먼저 각 카메라 좌표 프레임의 잠재 표현으로 인코딩된 다음 색상 및 밀도를 예측하기 전에 중간 레이어에서 풀링됩니다.
- 모델은 실제 이미지와 기존 볼륨 렌더링 기술을 사용하여 렌더링된 뷰 간의 reconstruction loss로 supervised됩니다.
PixelNeRF의 장점
- 정답값(GT) 3D shape 또는 object mask와 같은 추가 supervision 없이 이미지의 dataset에서 학습 가능합니다.
- 표준 좌표 프레임(object기준) 대신 입력 이미지의 카메라 좌표계(camera기준)에서 NeRF 표현을 예측합니다. 이는 보이지 않는 장면과 개체 범주에 대한 일반화에 필수적일 뿐만 아니라 여러 개체 또는 실제 장면이 있는 장면에 명확한 표준 좌표계가 존재하지 않기 때문에 유연성을 위해서도 필요합니다.
- 완전히 컨볼루션이므로 이미지와 출력 3D 표현 사이의 공간 정렬을 유지할 수 있습니다.
- 테스트 시간 최적화를 요구하지 않고 테스트 시간에 다양한 수의 포즈 입력 뷰를 통합할 수 있습니다.
Framework 효율성 및 유연성 증명 하기 위한 실험
- 효율성을 평가하기 위해 합성 및 실제 이미지 데이터 세트에 대한 광범위한 일련의 실험을 수행하였습니다. 더욱 나가가서(여느때와 다르게) 유연성을 입증하기 위해 ShapeNet 데이터 실험을 진행하였습니다.
- 실험은 pixelNeRF가 보이지 않는 개체 범주의 경우에도 category-specific 및 category-agnostic 설정 모두에 대해 단일 이미지 입력에서 novel-view 를 생성 할 수 있음을 보여줍니다.
- PixelNeRF는 ShapeNet bench mark에서 이전 모델들의 성능을 능가하는 것을 볼 수 있습니다.
- DTU 데이터 세트를 사용하여 실제 이미지에서 pixelNeRF의 기능을 테스트합니다.
✌ 개인 생각 ✌
우선 기존의 NeRF에 convolution을 함께 사용하는 방식을 채택한 것임을 알 수 있었습니다. 컨볼루션을 함께 함으로써 더 적은수의 장면 input을 내세우고 있으며, 이를 중점적으로 읽어야 할 것이라고 생각합니다. 발전 과정을 생각해보면 초기 이안 굿펠로우가 MLP로 먼저 GAN을 만들고 이를 사람들이 다른 기법들로 발전 시킨것 처럼 NeRF도 유사하게 발전 하고 있는 것을 느낄 수 있었습니다. benchmark를 다른 NeRF 모델들과 다르게 Shapenet을 채택한 것이 눈에 띕니다.
이와 별개로 논문을 작성한 글의 순서와 짜임새를 보면 앞선 NeRF들의 단점과 주장하고자하는 pixelNeRF의 장점이 대응되도록 나오는 것을 볼 수 있습니다. 또한 이를 증명하기 위한 실험에 대한 설명도 대응되도록 나오는 것을 볼 수 있습니다. 네트워크 구조와 아이디어는 단순하다고 생각 할 수 있지만 이러한 디테일들이 눈에 띄는 논문입니다.
몇가지 축약되어있는 단어나 용어들이 존재하는데 bilinear interpolation, grid, coordinate, canonical 등과 같은 단어들은 일단 논문을 다 읽고 동영상을 보면 어느정도 유추가 가능합니다. 물론 정확히 따로 공부를 하긴 해야겠죠:DRelated Work
- Novel view Synthesis 분야에서 적은 수의 이미지를 사용하는 모델들은 2.5D를 이용하며 이는 camera motion 범위에 있어서 제한적입니다.
- Learning-based 3D reconsturction 분야에서는 정답값인 3D dataset이 요구되지만 pixelNeRF는 그렇지 않습니다. 또한 대부분 object-centric(canonical)이지만 pixel-NeRF는 view centric입니다. 이를 통해 보이지 않는 범주나 확인되지 않는 category또한 유연하게 표현 가능합니다.
Reference : https://alexyu.net/pixelnerf/
pixelNeRF: Neural Radiance Fields from One or Few Images
Alex Yu Vickie Ye Matthew Tancik Angjoo Kanazawa UC Berkeley
alexyu.net
https://www.youtube.com/watch?v=voebZx7f32g&t=220s
#사용 이모지 (ming 말로는 window key + . 이란 단축키가 있다고 한다.. ㅎㅎ)
Emoji Homepage 👀 - Copy and paste emoji. 💨 Fast and 👌 Simple.
🤔 Find ☝ Your 😀 Emoji 💨 Fast & 👌 Simple! 👆 Click to copy and paste emojis ☺ Emoji Homepage is the easiest way to find and get emojis
emojihomepage.com
'논문 리뷰 > 오늘의 논문' 카테고리의 다른 글